Debjyoti Paul | দেবজ্যোতি পাল
Debjyoti Paul is a Staff Research Scientist at Meta, where his current work focuses on mid- and post-training of large language models (LLMs). His research interests span LLM post-training, audio LLMs, automatic speech recognition/translation (ASR/AST), language modeling (LM), representation learning, and spatio-temporal data analysis. He obtained his Ph.D. degree in Computer Science from the University of Utah, advised by Professor Feifei Li. He received his Masters and Bachelors degrees in Computer Science from the Indian Institute of Technology Kanpur and Institute of Engineering and Management, India respectively.
Contact

-
Academic Responsibilities
Program Committee Member
• International Conference on Very Large Data Bases (VLDB)
• International Conference on Data Engineering (ICDE)
Reviewer
• IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)
• ISCA Interspeech
• IEEE Automatic Speech Recognition and Understanding (ASRU) • IEEE Transactions on Knowledge and Data Engineering (TKDE)
• International Conference on Very Large Data Bases (VLDB)
• International Conference on Data Engineering (ICDE)
• IEEE Spoken Language Technology (IEEE SLT)
Teaching and TAs
• Advance Database Systems (Fall 2017)
• Data Mining (Spring 2017)
• Natural Language Processing (Fall 2016) -
University of Utah
Doctor of Philosophy
Computer Science
GPA: 3.96/4.0
Advisor: Prof. Feifei Li
Thesis: Data-Driven Spatio-Temporal Analysis for Multimode Data.
-
Institute of Engineering & Management
Bachelor of Technology (Rank < 10)
Computer Science & Engineering
-
Meta
Staff Research Scientist
AI Speech → LLM post-training (GenAI, MSL)
Location: Menlo Park, USA
-
Meta
Senior Research Scientist
AI Speech (Llama Speech, GenAI)
Location: Menlo Park, USA
-
Meta
Research Scientist
AI Speech (Reality Labs)
Location: Menlo Park, USA
-
Alibaba Group
Research Intern
Mentors: Feifei Li, Tieying Zhang, Hong Wu
Location: Sunnyvale, USA
-
Facebook
Summer Research Intern
Pages search improvement with AI
Mentor: Shawn Poindexter
Location: Seattle, USA
-
Amazon AI Lab
Summer Research Intern
Hyperparameter optimization in MxNet
Mentors: Baris Coskun, Ramesh Nallapati
Location: New York, USA
-
University of Utah
Research Assistant
InitialDLab, Database and data analysis Group
School of Computing
Location: Salt Lake City, USA
-
Flipkart
Software Developer (Data Engineer)
Data Platform Team
Built scalable environment for BigData processing.
Location: Bangalore, India.
VowelPrompt: Hearing Speech Emotions from Text via Vowel-level Prosodic Augmentation
Yancheng Wang, Osama Hanna, Ruiming Xie, Xianfeng Rui, Debjyoti Paul, Maohao Shen, Xuedong Zhang, et al.
International Conference on Learning Representations (ICLR), April 23-27, 2026, Rio de Janeiro, Brazil.
[Cite]
@inproceedings{wang2026vowelprompt, title={{VowelPrompt: Hearing Speech Emotions from Text via Vowel-level Prosodic Augmentation}}, author={Wang, Yancheng and Hanna, Osama and Xie, Ruiming and Rui, Xianfeng and Paul, Debjyoti and Shen, Maohao and Zhang, Xuedong and others}, booktitle={International Conference on Learning Representations (ICLR)}, year={2026}, }
R2S: Representation Learning for Speech Recognition with Guidance from Synthetic Data
Minh Tran, Debjyoti Paul, Yutong Pang, Laxmi Pandey, Kevin Jiang, Jinxi Guo, Ke Li, Shun Zhang, Xuedong Zhang, Xin Lei
26th Interspeech Conference, August 17-21, 2025, Rotterdam, The Netherlands.
Abstract We investigate the use of synthetic speech to enhance the performance of Automatic Speech Recognition (ASR) systems. While pre-trained ASR models have demonstrated impressive capabilities, their performance can still vary across different conditions and speakers. Conversely, text-to-speech technology allows for precise control over factors such as environmental noise and speaker accents, producing clean speech that poses fewer challenges for ASR systems. Building on this insight, we propose a novel method called R2S (Real-to-Synthetic), which aligns the representation spaces of real and synthetic speech. Our approach incorporates a Gradient Reversal Layer to promote invariant representations between real and synthetic speech, and a Residual-Vector Quantization module to generate pseudo-labels from synthetic speech, guiding the representations of real speech. Our experimental results on three datasets demonstrate that the proposed method can boost ASR performance by 4-5% and successfully align the representation space of real and synthetic speech. Our qualitative results further demonstrate that R2S can supress speaker-dependent features thanks to the alignment with synthetic speech.
@inproceedings{tran25_interspeech, title={{R2S: Real-to-Synthetic Representation Learning for Training Speech Recognition Models on Synthetic Data}}, author={Minh Tran and Debjyoti Paul and Yutong Pang and Laxmi Pandey and Jinxi Guo and Ke Li and Shun Zhang and Xuedong Zhang and Xin Lei}, year={2025}, booktitle = {{Interspeech 2025}}, pages = {3194--3198}, doi = {10.21437/Interspeech.2025-1109}, issn = {2958-1796}, }
A Domain Adaptation Framework for Speech Recognition Systems with Only Synthetic data
Minh Tran, Yutong Pang, Debjyoti Paul, Laxmi Pandey, Kevin Jiang, Jinxi Guo, Ke Li, Shun Zhang, Xuedong Zhang, Xin Lei
IEEE International Conference on Acoustics, Speech & Signal Processing (ICASSP), 6-11 April, 2025, Hyderabad, India.
[Abstract] | [PDF] | [Slides] | [Cite]
Abstract We introduce DAS (Domain Adaptation with Synthetic data), a novel domain adaptation framework for pre-trained ASR model, designed to efficiently adapt to various language-defined domains without requiring any real data. In particular, DAS first prompts large language models (LLMs) to generate domain-specific texts before converting these texts to speech via text-to-speech technology. The synthetic data is used to fine-tune Whisper with Low-Rank Adapters (LoRAs) for targeted domains such as music, weather, and sports. We introduce a novel one-pass decoding strategy that merges predictions from multiple LoRA adapters efficiently during the auto-regressive text generation process. Experimental results show significant improvements, reducing the Word Error Rate (WER) by 10% to 17% across all target domains compared to the original model, with minimal performance regression in out-of-domain settings -1% on Librispeech test sets. We also demonstrate that DAS operates efficiently during inference, introducing an additional 9% increase in Real Time Factor (RTF) compared to the original model when inferring with three LoRA adapters.
@misc{minh2024dassynth, title={A Domain Adaptation Framework for Speech Recognition Systems with Only Synthetic data}, author={Tran, Minh and Pang, Yutong and Paul, Debjyoti and Pandey, Laxmi and Jiang, Kevin and Guo, Jinxi and Li, Ke and Zhang, Shun and Zhang, Xuedong and Lei, Xin}, year={2025}, pages={1-5}, booktitle={ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, doi={10.1109/ICASSP49660.2025.10887883} }
LLaMA based Punctuation Restoration With Forward Pass Only Decoding
Yutong Pang, Debjyoti Paul, Kevin Jiang, Xin Lei, Xuedong Zhang
Arxiv, 2024
Abstract This paper introduces two advancements in the field of Large Language Model Annotation with a focus on punctuation restoration tasks. Our first contribution is the application of LLaMA for punctuation restoration, which demonstrates superior performance compared to the established benchmark. Despite its impressive quality, LLaMA faces challenges regarding inference speed and hallucinations. To address this, our second contribution presents Forward Pass Only Decoding (FPOD), a novel decoding approach for annotation tasks. This innovative method results in a substantial 19.8x improvement in inference speed, effectively addressing a critical bottleneck and enhancing the practical utility of LLaMA for large-scale data annotation tasks without hallucinations. The combination of these contributions not only solidifies LLaMA as a powerful tool for punctuation restoration but also highlights FPOD as a crucial strategy for overcoming speed constraints.
@misc{yutong2024fpodllm, title={Towards scalable efficient on-device ASR with transfer learning}, author={ Yutong Pang and Debjyoti Paul and Kevin Jiang and Xin Lei and Xuedong Zhang}, year={2024}, archivePrefix={arXiv}, primaryClass={cs.AI}, }
Towards Scalable Efficient On-device ASR with Transfer Learning
Laxmi Pandey, Ke Li, Jinxi Guo, Debjyoti Paul, Arthur Guo, Jay Mahadeokar, Xuedong Zhang.
Arxiv, 2024
Abstract Multilingual pretraining for transfer learning significantly boosts the robustness of low-resource monolingual ASR models. This study systematically investigates three main aspects: (a) the impact of transfer learning on model performance during initial training or fine-tuning, (b) the influence of transfer learning across dataset domains and languages, and (c) the effect on rare-word recognition compared to non-rare words. Our finding suggests that RNNT-loss pretraining, followed by monolingual fine-tuning with Minimum Word Error Rate (MinWER) loss, consistently reduces Word Error Rates (WER) across languages like Italian and French. WER Reductions (WERR) reach 36.2% and 42.8% compared to monolingual baselines for MLS and in-house datasets. Out-of-domain pretraining leads to 28% higher WERR than in-domain pretraining. Both rare and non-rare words benefit, with rare words showing greater improvements with out-of-domain pretraining, and non-rare words with in-domain pretraining.
@misc{pandey2024scalableefficientondeviceasr, title={Towards scalable efficient on-device ASR with transfer learning}, author={Laxmi Pandey and Ke Li and Jinxi Guo and Debjyoti Paul and Arthur Guo and Jay Mahadeokar and Xuedong Zhang}, year={2024}, eprint={2407.16664}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2407.16664}, }
Recovering from Privacy-Preserving Masking with Large Language Models
Arpita Vats, Zhe Liu, Peng Su, Debjyoti Paul, Yingyi Ma, Yutong Pang, Zeeshan Ahmed, Ozlem Kalinli.
IEEE International Conference on Acoustics, Speech & Signal Processing (ICASSP), 14-19 April, 2024, Seoul, Korea.
[Abstract] | [PDF] | [Poster] | [Cite]
Abstract Model adaptation is crucial to handle the discrepancy between proxy training data and actual users data received. To effectively perform adaptation, textual data of users is typically stored on servers or their local devices, where downstream natural language processing (NLP) models can be directly trained using such in-domain data. However, this might raise privacy and security concerns due to the extra risks of exposing user information to adversaries. Replacing identifying information in textual data with a generic marker has been recently explored. In this work, we leverage large language models (LLMs) to suggest substitutes of masked tokens and have their effectiveness evaluated on downstream language modeling tasks. Specifically, we propose multiple pre-trained and fine-tuned LLM-based approaches and perform empirical studies on various datasets for the comparison of these methods. Experimental results show that models trained on the obfuscation corpora are able to achieve comparable performance with the ones trained on the original data without privacy-preserving token masking.
@misc{vats2023recovering, title={Recovering from Privacy-Preserving Masking with Large Language Models}, author={Arpita Vats and Zhe Liu and Peng Su and Debjyoti Paul and Yingyi Ma and Yutong Pang and Zeeshan Ahmed and Ozlem Kalinli}, year={2023}, eprint={2309.08628}, archivePrefix={arXiv}, primaryClass={cs.CL} }
Language Agnostic Data-Driven Inverse Text Normalization
Szu-Jui Chen, Debjyoti Paul, Yutong Pang, Peng Su, Xuedong Zhang
24th Interspeech Conference, 20-24 August, 2023, Dublin, Ireland.
[Abstract] | [PDF] | [Poster] | [Cite]
Abstract The rise of automatic speech recognition (ASR) models has created an urgent need for converting spoken language into written text to provide better user experiences. This has drawn the attention of researchers, particularly for real-time on-device ASR deployment, towards the inverse text normalization (ITN) problem. While data-driven ITN methods have shown great promise in recent studies, the lack of labeled spoken-written datasets is hindering the development for non-English data-driven ITN.
To bridge this gap, we propose a language-agnostic data-driven ITN framework that leverages data augmentation and neural machine translation specifically designed for real-time miniature models and low-resource languages. Additionally, we have developed an evaluation method for language-agnostic ITN models when only English data is available. Our empirical evaluation attests to the efficacy of this language-agnostic ITN modeling with data augmentation approach for multiple non-English languages.
@misc{chen_paul_23, author={Chen, Szu-Jui and Paul, Debjyoti and Pang, Yutong and Su, Peng and Zhang, Xuedong}, title={{Language Agnostic Data-Driven Inverse Text Normalization}}, publisher={ISCA Interspeech}, year={2023}, }
Improving Data Driven Inverse Text Normalization using Data Augmentation and Machine Translation
Debjyoti Paul, Yutong Pang, Szu-Jui Chen, Xuedong Zhang
23rd Interspeech Conference, Show and Tell, 18-22 September, 2022, Incheon, Korea.
Abstract Inverse text normalization (ITN) is used to convert the spoken form output of an automatic speech recognition (ASR) systemto a written form. Traditional handcrafted ITN rules can be complex to transcribe and maintain. Meanwhile neural modeling approaches require quality large-scale spoken-written pair examples in the same or similar domain as the ASR system (in-domain data), to train. Both these approaches require costly and complex annotation. In this paper, we present a data augmentation technique with neural machine translation that effectively generates rich spoken-written pairs for high and low resource languages effectively. We empirically demonstrate that ITN models (in target language) trained using our data augmentation with machine translation technique can achieve similar performance as ITN models (en) trained directly with in-domain language.
@inproceedings{paul22_interspeech, author={Debjyoti Paul and Yutong Pang and Szu-Jui Chen and Xuedong Zhang}, title={{Improving Data Driven Inverse Text Normalization using Data Augmentation and Machine Translation}}, year=2022, booktitle={Proc. Interspeech 2022}, pages={5221--5222} }
Improving Data Driven Inverse Text Normalization using Data Augmentation
Laxmi Pandey, Debjyoti Paul, Pooja Chitkara, Yutong Pang, Xuedong Zhang, Kjell Schubert, Mark Chou, Shu Liu, Yatharth Saraf
The arXiv, 2022. doi: 10.48550/arXiv.2207.09674
[Abstract] | [PDF] | [arXiv] | [Cite]
Abstract Inverse text normalization (ITN) is used to convert the spoken form output of an automatic speech recognition (ASR) system to a written form. Traditional handcrafted ITN rules can be complex to transcribe and maintain. Meanwhile neural modeling approaches require quality large-scale spoken-written pair examples in the same or similar domain as the ASR system (in-domain data), to train. Both these approaches require costly and complex annotations. In this paper, we present a data aug- mentation technique that effectively generates rich spoken-written numeric pairs from out-of-domain textual data with minimal human annotation. We empirically demonstrate that ITN model trained using our data augmentation technique consistently outperform ITN model trained using only in-domain data across all numeric surfaces like cardinal, currency, and fraction, by an overall accuracy of 14.44%.
@misc{https://doi.org/10.48550/arxiv.2207.09674, doi = {10.48550/ARXIV.2207.09674}, url = {https://arxiv.org/abs/2207.09674}, author = {Pandey, Laxmi and Paul, Debjyoti and Chitkara, Pooja and Pang, Yutong and Zhang, Xuedong and Schubert, Kjell and Chou, Mark and Liu, Shu and Saraf, Yatharth}, title = {Improving Data Driven Inverse Text Normalization using Data Augmentation}, publisher = {arXiv}, year = {2022}, }
Database Workload Characterization with Query Plan Encoders
Debjyoti Paul, Jie Cao, Feifei Li, Vivek Srikumar
48th International Conference on Very Large Databases (VLDB 2021), 4-9 September, Sydney, Australia. doi: 10.14778/3503585.3503600, VLDB 2022.
[Abstract] | [PDF] | [Poster] | [Video] | [Cite]
Abstract Smart databases are adopting artificial intelligence (AI) technologies to achieve instance optimality, and in the future, databases will come with prepackaged AI models within their core components. The reason is that every database runs on different workloads, demands specific resources, and settings to achieve optimal performance. It prompts the necessity to understand workloads running in the system along with their features comprehensively, which we dub as workload characterization.To address this workload characterization problem, we propose our query plan encoders that learn essential features and their correlations from query plans. Our pretrained encoders captures the structural and the computational performance of queries independently. We show that our pretrained encoders are adaptable to workloads that expedites the transfer learning process. We performed independent assessments of structural encoder and performance encoders with multiple downstream tasks. For the overall evaluation of our query plan encoders, we architect two downstream tasks (i) query latency prediction and (ii) query classification. These tasks show the importance of feature-based workload characterization. We also performed extensive experiments on individual encoders to verify the effectiveness of representation learning, and domain adaptability.
@article{10.14778/3503585.3503600, author = {Paul, Debjyoti and Cao, Jie and Li, Feifei and Srikumar, Vivek}, title = {Database Workload Characterization with Query Plan Encoders}, year = {2021}, issue_date = {December 2021}, publisher = {VLDB Endowment}, volume = {15}, number = {4}, issn = {2150-8097}, url = {https://doi.org/10.14778/3503585.3503600}, doi = {10.14778/3503585.3503600}, journal = {Proc. VLDB Endow.}, month = {dec}, pages = {923–935}, numpages = {13} }
Semantic Embedding for Regions of Interest
Debjyoti Paul, Feifei Li. Jeff M. Phillips
The International Journal on Very Large Data Bases (VLDB Journal), 2021. doi: 10.1007/s00778-020-00647-0
[Abstract] | [PDF] | [Demo] | [Poster] | [Slides] | [Cite]
Abstract The available spatial data are rapidly growing and also diversifying. One may obtain in large quantities information such as annotated point/place of interest (POIs), check-in comments on those POIs, geo-tagged microblog comments, and demarked regions of interest (ROI). All sources interplay with each other, and together build a more complete picture of the spatial and social dynamics at play in a region. However, building a single fused representation of these data entries has been mainly rudimentary, such as allowing spatial joins. In this paper, we extend the concept of semantic embedding for POIs (points of interests) and devise the first semantic embedding of ROIs, and in particular ones that captures both its spatial and its semantic components. To accomplish this, we develop a multipart network model capturing the relationships between the diverse components, and through random-walk-based approaches, use this to embed the ROIs. We demonstrate the effectiveness of this embedding at simultaneously capturing both the spatial and semantic relationships between ROIs through extensive experiments. Applications like popularity region prediction demonstrate the benefit of using ROI embedding as features in comparison with baselines.
@article{paul2021semantic, title={Semantic embedding for regions of interest}, author={Paul, Debjyoti and Li, Feifei and Phillips, Jeff M}, journal={The VLDB Journal}, pages={1--21}, year={2021}, publisher={Springer} }
AI Pro: Data Processing Framework for AI Models
Richie Frost, Debjyoti Paul, Feifei Li.
35th IEEE International Conference on Data Engineering (ICDE 2019), 8-12 April, 2019. Macau, China. doi: 10.1109/ICDE.2019.00219
[Abstract] | [Link] | [PDF] | [Poster] | [Demo] | [Cite]
Abstract We present AI Pro, an open-source framework for data processing with Artificial Intelligence (AI) models. Our framework empowers its users with immense capability to transform raw data into meaningful information with a simple configuration file. AI Pro’s configuration file generates a data pipeline from start to finish with as many data transformations as desired. AI Pro supports major deep learning frameworks and Open Neural Network Exchange (ONNX), which allows users to choose models from any AI frameworks supported by ONNX. Its wide range of features and user friendly web interface grants everyone the opportunity to broaden their AI application horizons, irrespective of the user’s technical expertise. AI Pro has all the quintessential features to perform end-to-end data processing, which we demonstrate using two real world scenarios.
@inproceedings{frost2019ai, title={AI pro: Data processing framework for AI models}, author={Frost, Richie and Paul, Debjyoti and Li, Feifei}, booktitle={2019 IEEE 35th International Conference on Data Engineering (ICDE)}, pages={1980--1983}, year={2019}, organization={IEEE} }
Bursty Event Detection Throughout Histories
Debjyoti Paul, Yanqing Peng, Feifei Li.
35th IEEE International Conference on Data Engineering (ICDE 2019), 8-12 April, 2019. Macau, China. doi: 10.1109/ICDE.2019.00124.
[Abstract] | [Link] | [PDF] | [Poster] | [Cite]
Abstract The widespread use of social media and the active trend of moving towards more web- and mobile-based reporting for traditional media outlets have created an avalanche of information streams. These information streams bring in first-hand reporting on live events to massive crowds in real time as they are happening. It is important to study the phenomenon of burst in this context so that end-users can quickly identify important events that are emerging and developing in their early stages. In this paper, we investigate the problem of bursty event detection where we define burst as the acceleration over the incoming rate of an event mentioning. Existing works focus on the detection of current trending events, but it is important to be able to go back in time and explore bursty events throughout the history, while without the needs of storing and traversing the entire information stream from the past. We present a succinct probabilistic data structure and its associated query strategy to find bursty events at any time instance for the entire history. Extensive empirical results on real event streams have demonstrated the effectiveness of our approach.
@inproceedings{paul2019bursty, title={Bursty event detection throughout histories}, author={Paul, Debjyoti and Peng, Yanqing and Li, Feifei}, booktitle={2019 IEEE 35th International Conference on Data Engineering (ICDE)}, pages={1370--1381}, year={2019}, organization={IEEE} }
Geotagged US Tweets as Predictors of County-Level Health Outcomes, 2015–2016
Quynh C. Nguyen, Matt McCullough, Hsien-wen Meng, Debjyoti Paul, Dapeng Li, Suraj Kath, Geoffrey Loomis, Elaine O. Nsoesie, Ming Wen, Ken R. Smith, Feifei Li.
American Journal of Public Health, September, 2017, doi: 10.2105/AJPH.2017.303993
[Abstract] | [Link] | [PDF] | [Cite]
OBJECTIVES: Scarcity of consistently constructed environmental characteristics limits understanding of the impact of contextual factors on health. Our aim was to leverage geotagged Twitter data to create national indicators of the social environment, with small-area indicators of prevalent sentiment and social modeling of health behaviors. We then test associations with county-level health outcomes, controlling for demographic characteristics. METHODS: We utilized Twitter's Streaming Application Programming Interface (API) to continuously collect a random 1% subset of publicly available geo-located tweets. Approximately 80 million geotagged tweets from 603,363 unique Twitter users were collected in a 12-month period (April 2015- March 2016). RESULTS: Across 3135 US counties, Twitter indicators of happiness, food, and physical activity were associated with lower premature mortality, obesity, and physical inactivity. Alcohol use tweets predicted higher alcohol-use related mortality. CONCLUSIONS: Social media represents a new type of real-time data that may enable public health officials to examine movement of norms, sentiment, and behaviors that may portend emerging issues or outbreaks—thus providing a way to intervene to prevent adverse health events and measure the impact of health interventions.
@article{nguyen2017geotagged, title={Geotagged US tweets as predictors of county-level health outcomes, 2015--2016}, author={Nguyen, Quynh C and McCullough, Matt and Meng, Hsien-wen and Paul, Debjyoti and Li, Dapeng and Kath, Suraj and Loomis, Geoffrey and Nsoesie, Elaine O and Wen, Ming and Smith, Ken R and others}, journal={American journal of public health}, volume={107}, number={11}, pages={1776--1782}, year={2017}, publisher={American Public Health Association} }
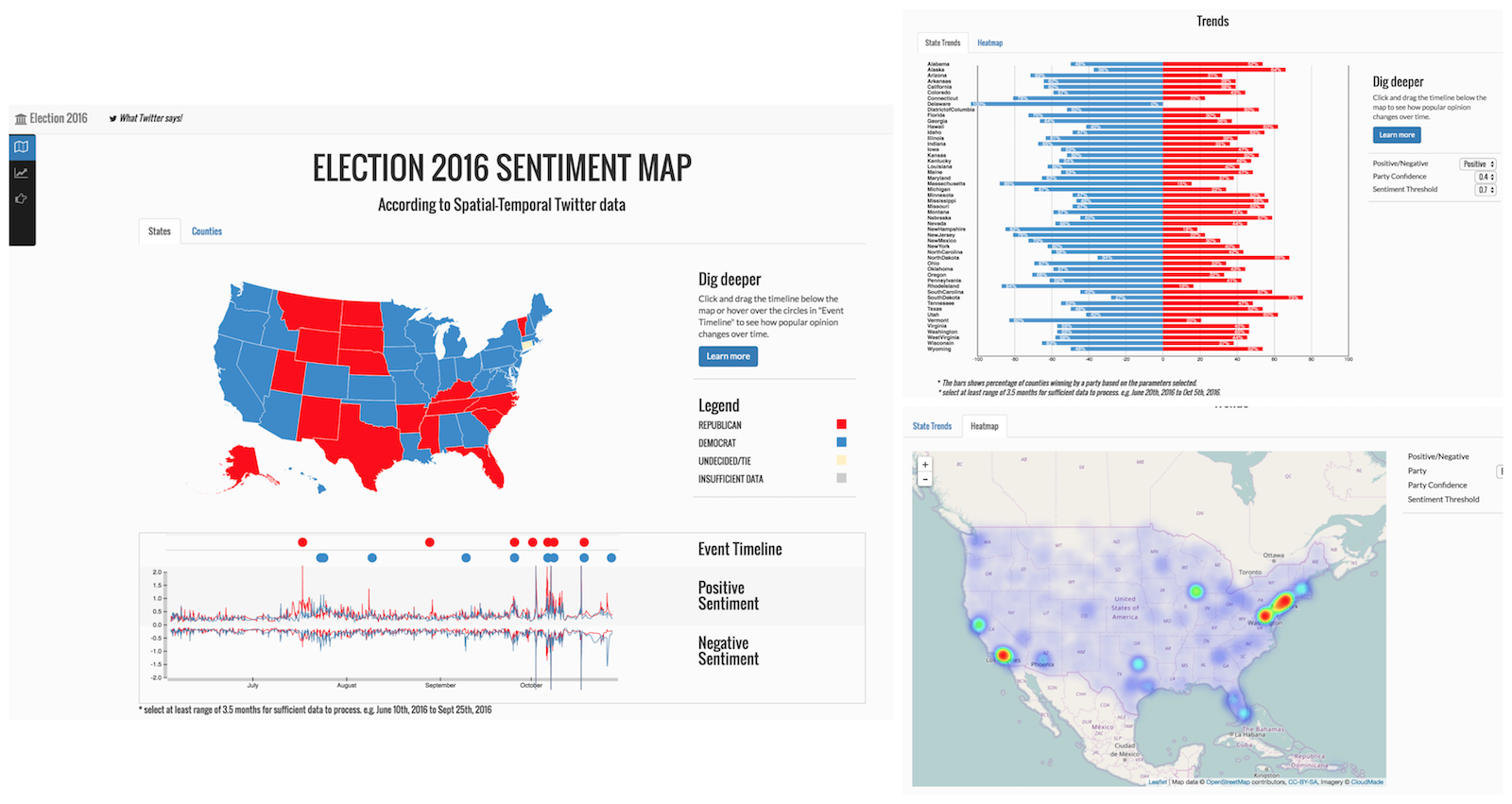
Compass: Spatio Temporal Sentiment Analysis of US Election, What twitter says!
Debjyoti Paul, Feifei Li, Murali Krishna Teja, Yu Xin, Richie Frost
SIGKDD 2017, 23rd SIGKDD Conference on Knowledge Discovery and Data Mining, Aug 13-17, Halifax, Canada. doi: 10.1145/3097983.3098053
[Abstract] | [PDF] | [Link] | [Video] | [Cite]
Abstract With the widespread growth of various social network tools and platforms, analyzing and understanding societal response and crowd reaction to important and emerging social issues and events through social media data is increasingly an important problem. However, there are numerous challenges towards realizing this goal effectively and efficiently, due to the unstructured and noisy nature of social media data. The large volume of the underlying data also presents a fundamental challenge. Furthermore, in many application scenarios, it is often interesting, and in some cases critical, to discover patterns and trends based on geographical and/or temporal partitions, and keep track of how they will change overtime. This brings up the interesting problem of spatio-temporal sentiment analysis from large-scale social media data. This paper investigates this problem through a data science project called ``US Election 2016, What Twitter Says’‘. The objective is to discover sentiment on twitter towards either the democratic or the republican party at US county and state levels over any arbitrary temporal intervals, using a large collection of geotagged tweets from a period of 6 months leading up to the US presidential election in 2016. Our results demonstrate that by integrating and developing a combination of machine learning and data management techniques, it is possible to do this at scale with effective outcomes. The results of our project have the potential to be adapted towards solving and influencing other interesting social issues such as building neighborhood happiness and health indicators.
@article{debjyoti2017compass, title={Compass: Spatio temporal sentiment analysis of us election}, author={Debjyoti, Paul and Feifei, Li and Murali, Krishna and Xin, Yu and Richie, Frost}, journal={Knowledge Discovery from Data (KDD 17)}, year={2017} }
Social media indicators of the food environment and state health outcomes
Nguyen. Quynh, Meng. H, Li. D, Kath. Suraj, McCullough. Matt, Paul. Debjyoti, Kanokvimankul. P, Nguyen. T, Li. Feifei,
Public Health, American Public Health Association, 148, 120-128. doi: 10.1016/j.puhe.2017.03.013
[Abstract] | [PDF] | [Link] | [Cite]
OBJECTIVES: Contextual factors can influence health through exposures to health-promoting and risk-inducing factors. The aim of this study was to (1) build, from geotagged Twitter and Yelp data, a national food environment database and (2) to test associations between state food environment indicators and health outcomes. STUDY DESIGN: This is a cross-sectional study based upon secondary analyses of publicly available data. METHODS: Using Twitter's Streaming Application Programming Interface (API), we collected and processed 4,041,521 food-related, geotagged tweets between April 2015 and March 2016. Using Yelp's Search API, we collected data on 505,554 unique food-related businesses. In linear regression models, we examined associations between food environment characteristics and state-level health outcomes, controlling for state-level differences in age, percent non-Hispanic white, and median household income. RESULTS: A one standard deviation increase in caloric density of food tweets was related to higher all-cause mortality (+46.50 per 100,000), diabetes (+0.75%), obesity (+1.78%), high cholesterol (+1.40%), and fair/poor self-rated health (2.01%). More burger Yelp listings were related to higher prevalence of diabetes (+0.55%), obesity (1.35%), and fair/poor self-rated health (1.12%). More alcohol tweets and Yelp bars and pub listings were related to higher state-level binge drinking and heavy drinking, but lower mortality and lower percent reporting fair/poor self-rated health. Supplemental analyses with county-level social media indicators and county health outcomes resulted in finding similar but slightly attenuated associations compared to those found at the state level. CONCLUSIONS: Social media can be utilized to create indicators of the food environment that are associated with area-level mortality, health behaviors, and chronic conditions.
@article{nguyen2017social, title={Social media indicators of the food environment and state health outcomes}, author={Nguyen, QC and Meng, H and Li, D and Kath, S and McCullough, M and Paul, D and Kanokvimankul, P and Nguyen, TX and Li, F}, journal={Public Health}, volume={148}, pages={120--128}, year={2017}, publisher={Elsevier} }
Multi-objective Evolution based Dynamic Job Scheduler in Grid
Debjyoti Paul, Sanjeev K. Aggarwal,
The 8th International Conference on Complex, Intelligent, and Software Intensive Systems (CISIS 2014), July 2nd – 4th, 2014, Birmingham, UK. doi:10.1109/CISIS.2014.50
[Abstract] | [PDF] | [Link] | [Cite]
Abstract Grid computing is a high performance computing environment to fulfill large-scale computational demands. It can integrate computational as well as storage resources from different networks and geographically dispersed organizations into a high performance computational & storage platform. It is used to solve complex computational-intensive problems, and also provide solution to storage-intensive applications with connected storage resources. Scheduling of user jobs properly on the heterogeneous resources is an important task in a grid computing environment. The main goal of scheduling is to maximize resource utilization, minimize waiting time of jobs, reduce energy consumption, minimize cost to the user after satisfying constraints of jobs and resources. We can trade off between the required level of quality of service, the deadline and the budget of user. In this paper, we propose a Multi-objective Evolution-based Dynamic Scheduler in Grid. Our scheduler have used Multi-objective optimization technique using Genetic algorithm with pareto front approach to find efficient schedules. It explores the search space vividly to avoid stagnation and generate near optimal solution. We propose that our scheduler provides a better grip on most features of grid from perspective of grid owner as well as user. Dynamic grid environment has forced us to make it a real time dynamic scheduler. A job grouping technique is proposed for grouping fine-grained jobs and for ease of computation. Experimentation on different data sets and on various parameters revealed effectiveness of multi- objective scheduling criteria and extraction of performance from grid resource.
@inproceedings{paul2014multi, title={Multi-objective evolution based dynamic job scheduler in grid}, author={Paul, Debjyoti and Aggarwal, Sanjeev K}, booktitle={2014 Eighth International Conference on Complex, Intelligent and Software Intensive Systems}, pages={359--366}, year={2014}, organization={IEEE} }
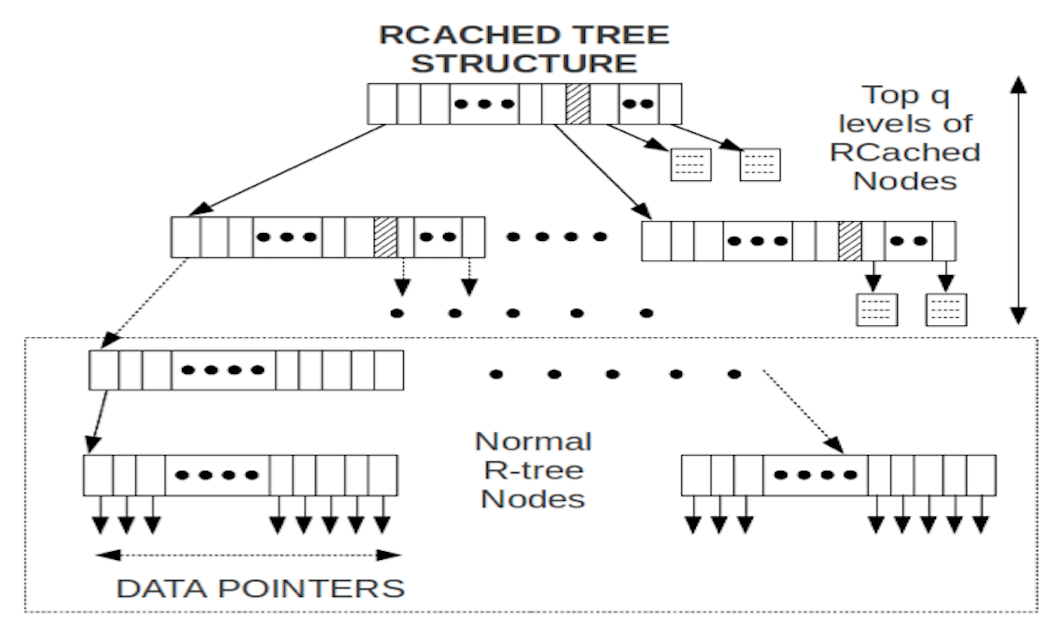
RCached-tree: An Index Structure for Efficiently Answering Popular Queries
Manash Pal, Arnab Bhattacharya, Debjyoti Paul
ACM International Conference on Information and Knowledge Management (CIKM 2013), Oct. 27–Nov. 1, 2013, San Francisco, CA, USA. doi:10.1145/2505515.2507817
[Abstract] | [PDF] | [Link] | [Cite]
Abstract In many applications of similarity searching in databases, a set of similar queries appear more frequently. Since it is rare that a query point with its associated parameters (range or number of nearest neighbors) will repeat exactly, intelligent caching mechanisms are required to efficiently answer such queries. In addition, the performance of non-repeating and non-cached queries should not suffer too much either. In this paper, we propose RCached-tree, belonging to the family of R-trees, that aims to solve this problem. In every internal node of the tree up to a certain level, a portion of the space is reserved for storing popular queries and their solutions. For a new query that is encompassed by a cached query, this enables bypassing the traversal of lower levels of the subtree corresponding to the node as the answers can be obtained directly from the result set of the cached query. The struc- ture adapts itself to varying query patterns; new popular queries replace the old cached ones that are not popular any more. Queries that are not popular as well as insertions, deletions and updates are handled in the same manner as in a general R-tree. Experiments show that the RCached-tree can outperform R-tree and other such structures by a signif- icant margin when the proportion of popular queries is 20% or more by reserving 30-40% of the internal nodes as cache.
@inproceedings{pal2013rcached, title={RCached-tree: an index structure for efficiently answering popular queries}, author={Pal, Manash and Bhattacharya, Arnab and Paul, Debjyoti}, booktitle={Proceedings of the 22nd ACM international conference on Information \& Knowledge Management}, pages={1173--1176}, year={2013} }
Lightweight Security Enhancement Protocol for Radio Frequency Identification(RFID)
Debjyoti Paul, Sumana Basu, Sukanya Ghosh
Proceedings of International Conference on Scientific Paradigm Shift In Information Technology & Management (SPSITM 2011), January 2011, Kolkata, INDIA.
[Abstract] | [PDF] | [Google Scholar] | [Cite]
Abstract Though RFID provides automatic object identification, yet it is vulnerable to various security threats that put consumer and organization privacy at stake. In this work, we have considered some existing security protocols of RFID system and analyzed the possible security threats at each level. We have modified those parts of protocol that have security loopholes and thus finally proposed a modified four-level security model that has the potential to provide fortification against security threats.
@inproceedings{basu2011lightweight, title={Lightweight Security Enhancement Protocol for Radio Frequency Identification (RFID)}, author={Basu, Sumana and Paul, Debjyoti and Ghosh, Sukanya}, booktitle={IEEE International Conference on SPSITM}, volume={2011}, year={2011} }
Multilevel Security Protocol using Radio Frequency Identification
Debjyoti Paul, Sumana Basu, Punit Beriwal
IEEE Paper, International Conference on Emerging Trends in Mathematics and Computer Applications–2010 Page no-544 to 547 , Sivakasi, Tamil Nadu.
@article{basumultilevel, title={Multilevel Security Protocol using Radio Frequency Identification (RFID)}, author={Basu, Sumana and Paul, Debjyoti and Ghosh, Sukanya and Beriwal, Punit and Saha, Himadri Nath} }
[Apr 2026] Our paper VowelPrompt: Hearing Speech Emotions from Text via Vowel-level Prosodic Augmentation accepted at ICLR 2026, Rio de Janeiro, Brazil.
[2025] Promoted to Staff Research Scientist at Meta.
[Aug 2025] Presented our research paper R2S: Representation Learning for Speech Recognition with Guidance from Synthetic Data at Interspeech 2025, Rotterdam, The Netherlands.
[Apr 2025] Our paper A Domain Adaptation Framework for Speech Recognition Systems with Only Synthetic Data presented at ICASSP 2025, Hyderabad, India.
[Dec 2023] Our paper Recovering from Privacy-Preserving Masking with Large Language Models accepted at ICASSP 2024.
[Nov 2023] Serving as a reviewer for ICASSP 2024.
[Aug 2023] Presented our research paper Language Agnostic Data-Driven Inverse Text Normalization at ISCA Interspeech 2023..
[Mar 2023] Serving as a reviewer for ISCA Interspeech 2023.
[Dec 2022] Invited Talk on Database Workload Characterization work at Microsoft's Gray Systems Lab. [Slides]
[Dec 2022] Serving as a reviewer for ICASSP 2023.
[Sep 2022] Presented our research paper Database Workload Characterization with Query Plan Encoders at VLDB 2022 Conference.
[Sep 2022] Our paper on Improving Data Driven Inverse Text Normalization using Data Augmentation and Machine Translation accepted at Interspeech 2022.
[Feb 2022] Promoted to Senior Research Scientist at Meta (former Facebook) in 2022.
[2021] Serving as a Program Committee Member and Reviwer for VLDB 2021 and ICDE 2021.
[Aug 2021] Paper accepted at VLDB Journal, Semantic Embedding for Regions of Interest (2021). Presented work at VLDB 2021 conference poster session.
[Mar 2020] Joined Facebook as a Research Scientist in 2020.
[Feb 2020]Completed PhD in Computer Science and Engineering on February 2020.
[Apr 2019] AI Pro: Data Processing Framework for AI Models paper accepted for ICDE 2019, library published here.
[Apr 2019] Bursty Event Detection Throughout Histories paper accepted for ICDE.
[Jan 2019] Passed PhD qualifier exam, the written qualifier part of the exam is available here.
[2018] Open sourced scrapy crawlers for public news agencies, now available here.
[2018] Published sentiment analysis model, now available in a github repository.
[2017] Compass: Spatio Temporal Sentiment Analysis paper accepted and presented at SIGKDD 2017.
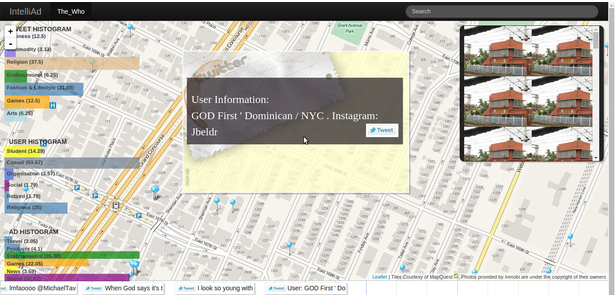
[2016] Spatio-temporal Sentiment Analysis Project estorm.org analyzed the sentiment of common people on US Election. It gained a lot of media coverage. (2016)
|
|
|
|
|
|
|
|
|
|
|

[2016] Open-sourced a modified style for latex-based acedemic poster making library Tikzposter, Github. (2016)
[2016] Open-sourced Wikipedia Search repository, build from scratch with page ranking algorithm, document relevance, and query processing in WikiSearch, Github. (2016)
[2016] Published Question Answering System in Github. Best poster in NLP course CS6340. 12 stars, 8 forks. (2016)
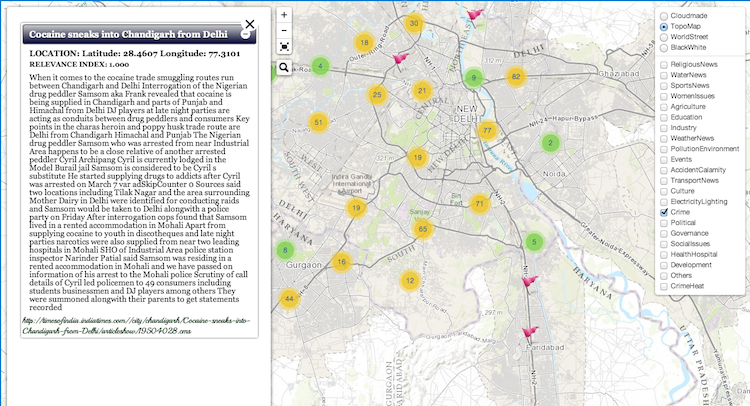
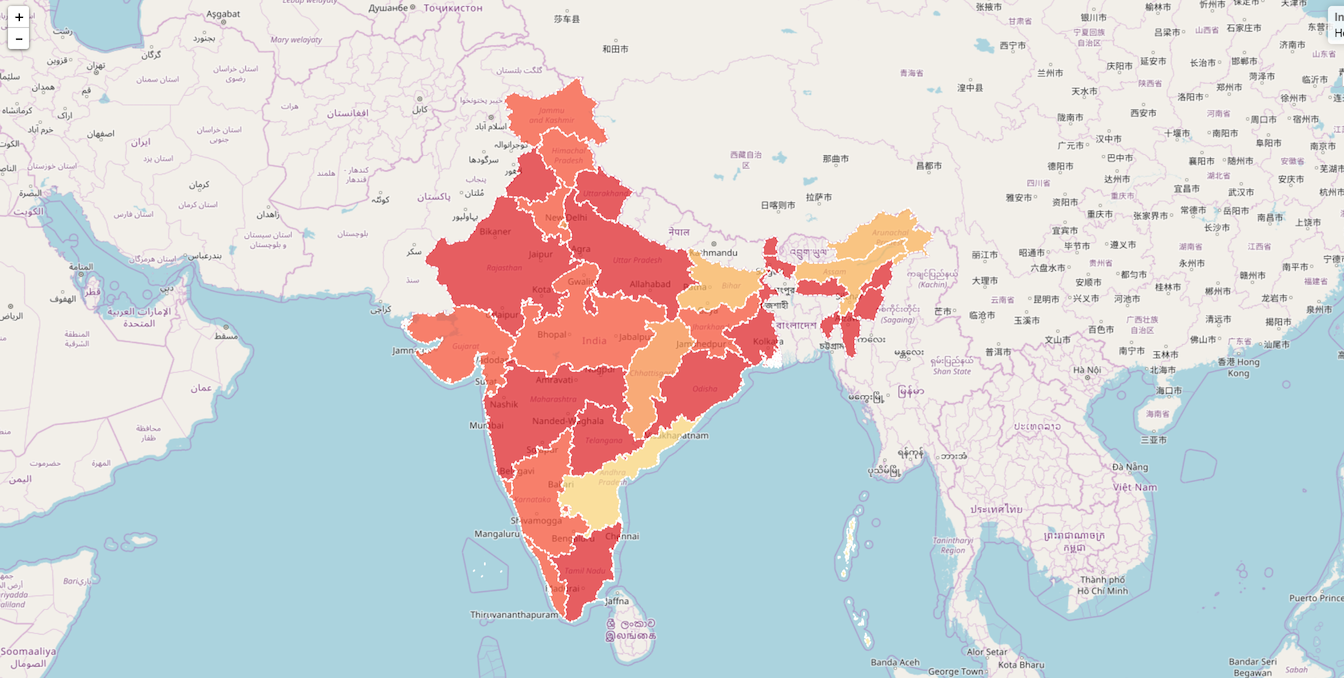
[2016] Building a National Neighborhood Dataset From Geotagged Twitter Data for Indicators of Happiness, Diet, and Physical Activity. JMIR 2016. Amassed a lot of media attention.
|
|
|
|
|
|
|

[2014] Multi-objective Evolution based Dynamic Job Scheduler in Grid paper accepted at CISIS 2014.
[2013]Ranked 3rd out of 39 M.Tech students of CSE department in Indian of Institute Technology, Kanpur M.Tech (2011-2013)
[2012]
[2012]
[2011]Achieved All India Rank of 7 in Indian Space Research Organization (ISRO) recruitment exam. (2011-2012)
[2011]
[2011]Amongst top 10 student of CSE department in Institute of Engineering Management, Kolkata, and awarded academic excellence for performance in B.Tech (2007-2011)